


背景
搜索引擎的缺点:1)返回大量的网页;2)候选太多,没有精准答案;3)无法满足迫切需求。
问答系统(QA)应运而生,可以解决这些痛点问题,更快速、更准确地向用户反馈答案。
知识库的优点:1)体量大,质量高;2)具有结构化特点,便于搜索查询;3)答案精准、简洁。
问答系统
目前有很多划分方法,按知识领域可以划分成:
1)封闭领域:特定领域,比如法律、金融、汽车等垂直领域。
2)开放领域:百科知识问答、闲聊等。
按答案来源可以划分成
1)知识库问答(Knowledge Base Question Answering,KBQA):基于结构化数据(检索式)
2)常问问题系统(Frequently Asked Questions,FAQs):基于问答对数据(检索式)
3)机器阅读理解(Machine Reading Comprehension,MRC):基于自由文本(抽取式、生成式)
知识库问答
知识的定义。例如“A 的女儿是 B,C 出生在上海,E 有1.88米高“这些客观事实就是一条条的知识,它们大多来源于百科网站,但是这些知识是非结构化的自然语言文本,导致计算机无法直接处理。
三元组的定义。例如一条知识“E 有1.88米高”可以转化成三元组为(E,身高,1.88米)。三元组的格式有很多种,可以为(主语,谓语,宾语)或者(头实体, 关系, 尾实体)或者(实体,属性,属性值)。
知识图谱的定义。知识图谱是一个有向图,由大量的三元组来构建,其中图中结点是三元组的主语,图中的边是三元组的谓语。这里的谓语可以是关系,也可以是属性。关系对应的是两个实体结点,而属性对应的是一个实体结点和一个字符串文本。
知识库问答的定义。给定一个自然语言问句,问答系统从现有的知识库中搜索相关的实体或属性值作为答案。问题都是客观事实型,不含有任何的主管色彩。在理解问题和搜索答案的过程中,涉及到实体提及识别、实体链接、属性链接和语义解析等多个自然语言处理子任务,再利用SQL、SPARQL等语言对知识库进行查询、推理获得相应的答案。具体过程如下图所示。
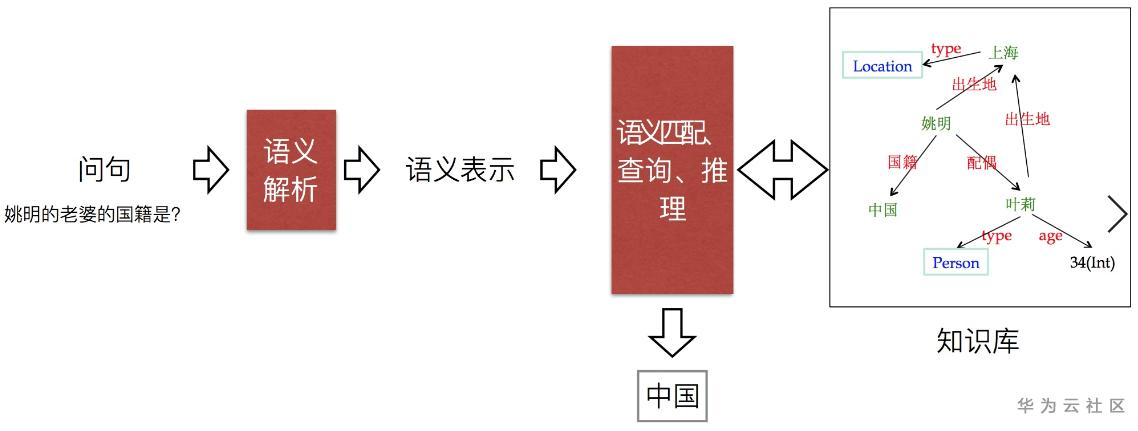
数据集和知识库。目前中英文都有大规模的标注数据集,包括简单问题和复杂问题,部分数据集提供逻辑查询。中文公开的问答对数据有NLPCC2015-2018 KBQA评测数据集、CCKS2018-2020 CKBQA 评测数据集等,公开的知识库有NLPCC评测知识库、CCKS评测知识库、Zhishi.me、XLore等,而英文公开的数据集有SimpleQuestions、WebQuestions、ComplexQuestions、GraphQuestions 等,知识库有Freebase、DBpedia、YAGO等。
KBQA 目前主流的方法
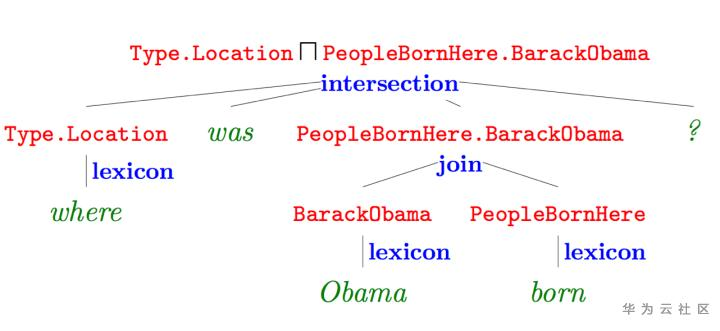
基于语义解析的方法
主要思想是将自然语言解析成一种逻辑表达式,然后查询知识库得出答案。下图绿色字体表示自然语言问句“where was Obama born”,蓝色字体表示对问句中的不同成分进行语义解析,红色字体表示每一成分对应的解析结果,最终结果是树的根节点,即逻辑表达式。主要过程:首先建立词汇表,将问句中的不同成分链接到知识库中的实体或者关系,然后自下而上构建一颗语法分析树。一个问句可以生成不同的候选语义解析结果,通过训练分类模型计算它们的概率分布。
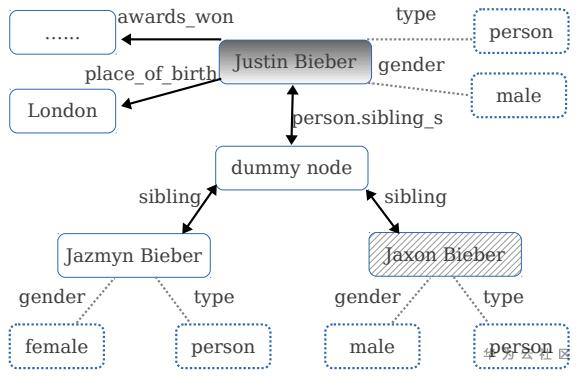
基于信息检索的方法
主要思想是先对问句进行实体提及识别,然后链接到知识库中对应的实体,检索该实体的子图,将节点或边作为候选答案。然后分别对问句和候选答案提取特征,利用排序模型对候选答案进行筛选。例如问题:“what is the name of Justin Bieber brother?”,先将问题的依存句法树转化成一个问题图,提取四个问题特征,包括问题词qword、问题焦点qfocus、问题主题词qtopic和问题中心动词qverb。下图是实体的一个子图,图中的节点和边是问句的候选答案,其特征是子图中的属性和关系。选择答案的过程可以看做是一个二分类问题,即判断候选答案是否为正确答案。通过问题-答案的所有特征数据,训练一个分类器模型,常用的模型有SVM,MLP和LR等。
基于向量建模的方法
该方法属于信息检索的一种。首先以实体的子图作为候选答案。然后将问句和候选答案分别映射为一种分布式表示,通过训练模型使得正确答案和问句的关联得分最高。如下图所示,左边是问句的分布式表示,右边是候选答案的分布式表示,然后采用点乘的方式对候选答案进行打分和排序。问题表示的维度包括词表的大小、知识库中实体的个数和关系的个数,类似于one-hot词袋模型。候选答案表示和问题表示类似,去除了知识库中的信息。将两者的表示输入到多维矩阵中进行转,映射到同一个语义空间,然后计算得分。

基于深度学习的方法
该方法是对上述两种主流方法进行了改进和扩展。目前基于深度学习的方法无须像模板方法那样人工编写大量模板,也无须像语义分析方法中人工编写大量规则,整个过程都是自动进行。但缺点也很明显,它目前只能处理简单问题和单边关系,对于复杂问题不如两种传统方法效果好。同时由于DL方法通常不包含聚类操作,因此对于一些时序敏感性问题无法很好的处理。常用的深度学习模型有卷积神经网络、长短期记忆网络、记忆网络、注意力机制等。




留言评论
暂无留言