


目录
大数据神器谱
VMware简介
安装注意
Linux简介
安装介绍
Hadoop简介
安装介绍
Spark简介
安装介绍
Pycharm简介
安装介绍
Anaconda简介
安装介绍
安装步骤
VMware15.5(虚拟机)安装教程
资源包下载
Hadoop安装
Spark安装
Anaconda安装
Pycharm安装
pycharm配置与破解
破解步骤
Anaconda python版本降级
添加虚拟机spark环境变量
python 3.8 降级 3.7
Pycharm美工配置
每文一语
大数据神器谱
大数据的时代,必定有一场与数据的生死搏斗,狭路相逢勇者胜,你的思想决定你的高度,没有必然的成功,只有不懈的尝试!
如果不能逆风翻盘,就一定要向阳而生!
针对Linux,Hadoop,Spark我都有安装好的文件包,直接用我的文件即可,就可以直接只用该环境,文件镜像每个约7GB左右,资源无法上传,有需要的可以私信我,或者评论区留言QQ账号加自己的CSDN账号昵称!
VMware简介
VMware是一个虚拟PC的软件,可以在现有的操作系统上虚拟出一个新的硬件环境,相当于模拟出一台新的PC,实现在一台机器上真正同时运行两个独立的操作系统。VMware(虚拟机)是指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统,通过它可在一台电脑上同时运行更多的Microsoft Windows、Linux、Mac OS X、DOS系统。

安装注意
有的VMware安装之后,打开电脑会蓝屏,可谓是让不少人头疼,以为又是系统出了什么幺蛾子了,其实不是这样的,VMware15对Win10也太不友好了吧,原因是电脑在自动更新系统之后,会起冲突,那么解决的方法就是:安装高版本的VMware,比如16版本的。当然具体的解决方法也还是有的,只是在电脑的世界里,0 1 的美好我们不能理解,还是不要去打扰他们的二人世界了吧,我们用最简单的方法做最有价值的事情,何乐而不为?
Linux简介
Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯·本纳第克特·托瓦兹于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。

安装介绍
Linux安装通道开启,点击此处查看!
当然对于Linux的安装,也不是很麻烦,因为在Linux安装我们首先要去安装VMware,我们已经安装好了,所以已经是游刃有余的操作了!
Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。

安装介绍
对于Hadoop的安装,是非常的繁琐的,从安装Ubuntu,在去安装Hadoop里面的各个组件:hdfs,hbase,hive,flume,sqoop.......说实话不太喜欢把大把的时间花在这个里面,还是那句话以最简单的途径做最有效率的事情,我们要学会站在巨人的肩膀上去窥探世界的神奇之处。
Spark简介
Spark首先是一个大规模数据处理的统一分析引擎,它是类与Hadoop MapReduce的通用并行框架,专门为大数据处理的一个快速计算引擎。如果说Hadoop是大数据的第一把利剑,那么毫无疑问spark就是大数据分析与计算的第二把利剑,spark具有下面四个特点:
快速: 在相同的实验环境下处理相同的数据,若在内存中运行,那么Spark要比MapReduce快100倍(只是在逻辑回归测试中)。
通用:Spark 是一个通用引擎,可用它来完成各种运算,包括 SQL 查询、文本处理、机器学习、实时流处理等。我们之前花费大量的时间去学习SQL的规范与语法,就是为了在后面有更好的突破和发展。
易用:Spark提供了高级 API,应用开发者只用专注于应用计算本身即可,而不用关注集群本身,这使得Spark更简单易用。至于提供了高级的API,那么我们知道Python是一个胶水语言,一般在智能的分析里面我们还是要利用Python的特性,提供pyspark这个模块进行我们更加快速方便的操作。
兼容性好:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。
安装介绍
安装spark必然要安装到Hadoop环境里面,这样是最好的选择,如果没有也是可以的,直接安装到虚拟机的Ubuntu里面,或者Windows里面。
Pycharm简介
对于pycharm而言,估计很多人都不陌生,这是Python编程的神器,也是我们进行数据处理和分析的强大的编辑器,个人觉得比VScode好用,还是那句话:适合自己才是最好的,哈哈哈!至于我们为什么要在虚拟环境里面安装pycharm,这是因为我们日常开发都是在虚拟环境,比如Linux里面,作为初学者和学者来说,一般在Windows里面进行操作更加好,也可以说更加的适合,从基本语法到爬虫,再到数据分析,最后再到大数据处理的一个必要编程语言,我们的Python一直都是最好的工具,那就说明pycharm也是更好的工具,正所谓:磨刀不误砍柴工!

安装介绍
本次安装是在Hadoop和Spark环境里面安装的pycharm,一方面是为了在虚拟机里面处理大数据集,一方面是为了在使用spark的时候,可以直接连接虚拟机里面的spark进行计算操作,和我们之前用pycharm去连接虚拟机里面的Hadoop的hive一样,用大数据的分布式平台,在加上pycharm的便利,可谓是如虎添翼!注意如果是自己去官网下载,自己去安装一定要注意是下载的Linux版本的pycharm哟!
Anaconda简介
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。 [1] 因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
安装介绍
一般安装好anaconda之后,有的人觉得没有必要安装anaconda,因为觉得麻烦,他们觉得直接使用pycharm里面的自带编译器,也可以,但是我觉得anaconda里面无论是在安装库还是在调用,我个人觉得还是比较好,虽然有点麻烦,但是是值得的!
安装步骤
VMware15.5(虚拟机)安装教程
1.鼠标右击【VMware Workstation Pro 15.5.0】压缩包选择【解压到 VMware Workstation Pro 15.5.0】
2.打开解压后的文件夹,鼠标右击【VMware-workstation-full-15.5.0-14665864】选择【以管理员身份运行】。
3.点击【下一步】。
4.勾选【我接受许可协议中的条款】,点击【下一步】。
5.点击【更改…】可更改安装位置(建议不要安装在C盘,可以在D盘或其它磁盘下新建一个“VM”文件夹),点击【下一步】。
6.取消勾选【启动时检查……】和【加入VMware……】,点击【下一步】。
7.点击【下一步】。
8.点击【安装】。
9.软件安装中(大约需要3分钟)。
10.点击【许可证】。
11.输入许可证密钥【UY758-0RXEQ-M81WP-8ZM7Z-Y3HDA】(以下可任意输入一组),点击【输入】。
12.安装完成,点击【完成】。
13.双击桌面【VMware Workstation Pro】图标启动软件。
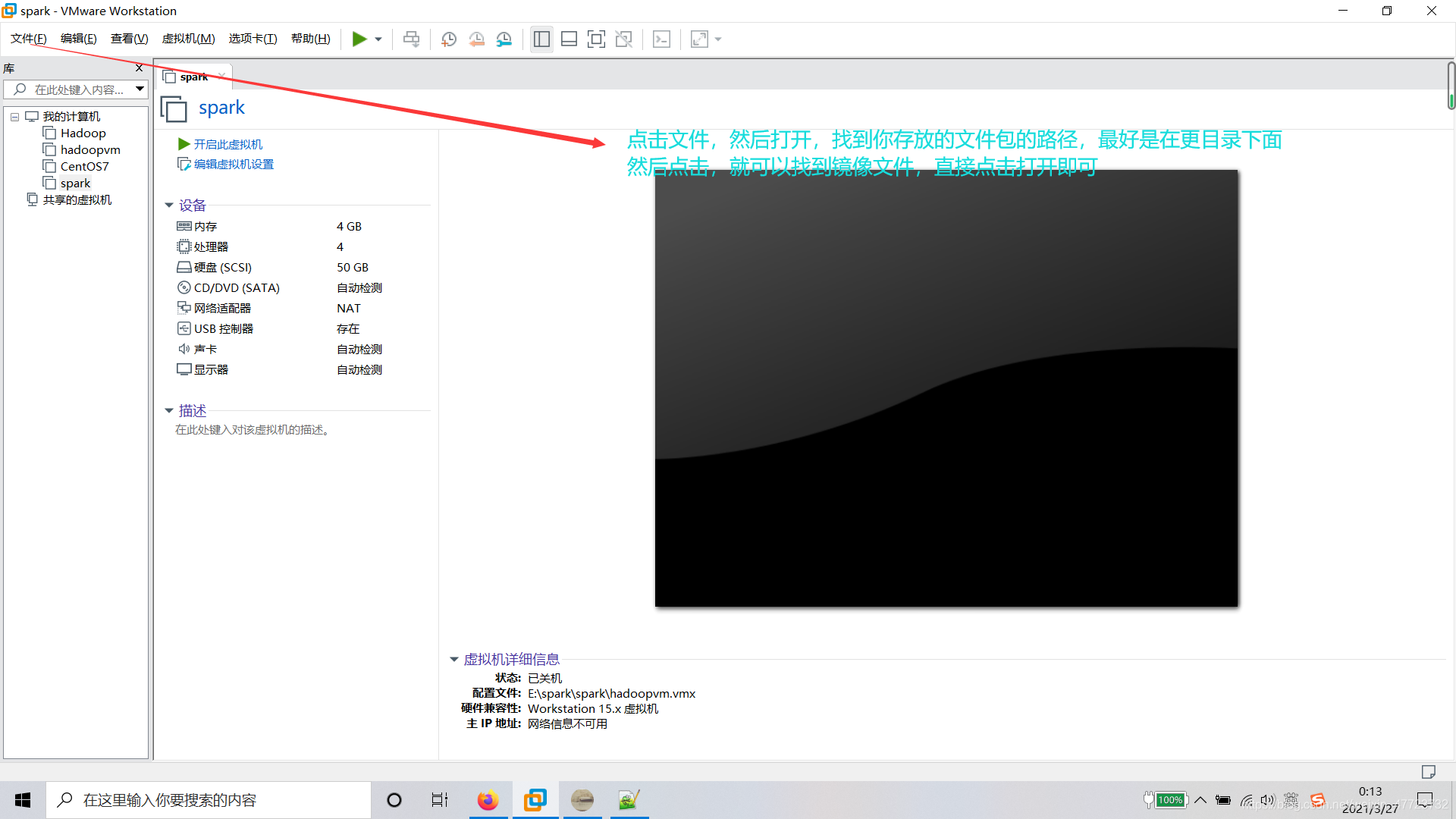
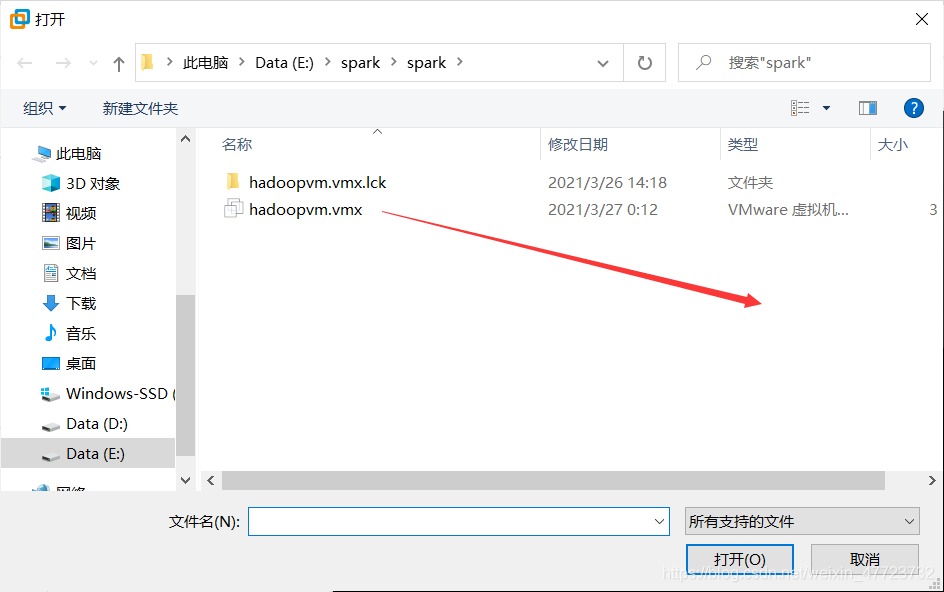
16版本的一样的道理,只是安装包不一样,根据你的需要安装属于你自己的神器吧!
资源包下载
点击此处下载VMware15
点击此处下载VMware16
涉及到版权原因,无法上传,若有需要请评论区留言QQ邮箱!
Hadoop安装
首当其冲就是Ubuntu的安装了,这个是基础,这里推荐一个博主的博文,讲的非常详细,这就是站在巨人的肩膀上来解决问题,哈哈哈!
通道开启,点击此处查看!
Ubuntu安装好之后,我们需要安装Hadoop了

之前在 淘宝数据可视化大屏案例(Hadoop实验) 这个文章里面附着了Hadoop的全套安装教程的哈,自己点进去查看,然后按照相应的步骤就可以安装好了!
Spark安装
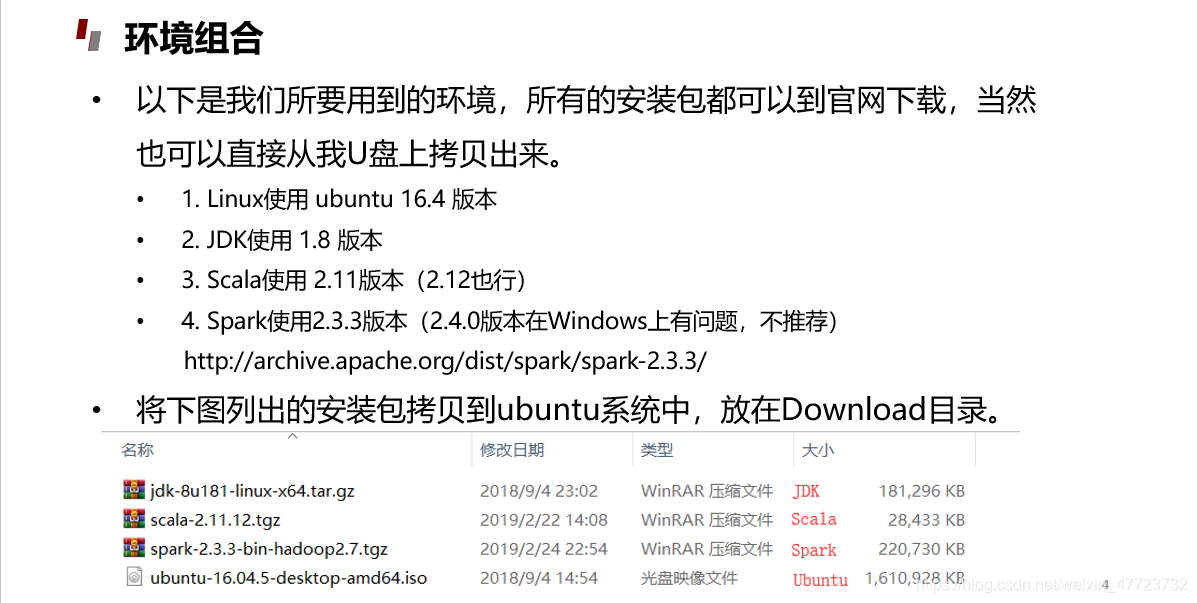
对于spark的安装我直接给出部分截图资源,详情请自己去下载,有基于Linux的安装和Windows的安装,都可以!

基于Linux安装步骤文档资源下载!
基于Windows安装步骤资源下载!
Linux环境下安装spark的所有资源下载!
Windows环境下安装spark的所有资源下载!
Anaconda安装
Anaconda安装包资源基于Linux版本下载!点击此处下载!
首先安装Anaconda的时候,要明确你Anaconda文件放在哪里的,找到该文件的目录,虽然在虚拟机里面不存在C盘,也不涉及到文件放在哪里会出现系统卡顿的情况,但是我们还是要自己规范一下,因为规范化是一个开发者必要的职业素养。

切换到该文件的路径下面

开始安装

输入yes接受许可,进行安装所需文件!!!

更多点击完后出现(注意:回车一直按着到最后会出现很多问你yes或者no的问题)
输入:yes
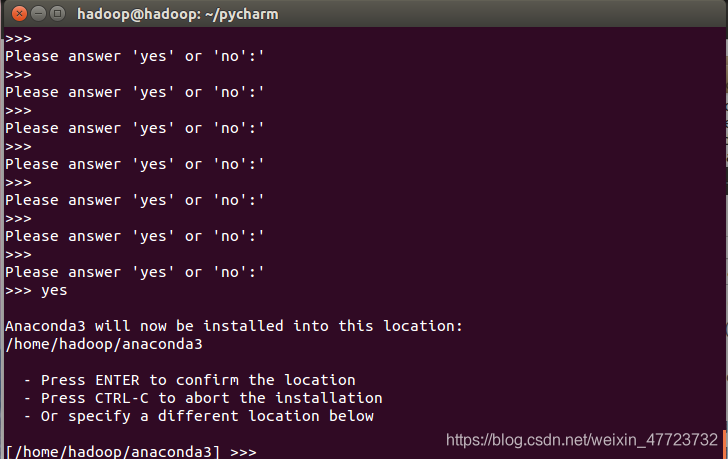
回答完yes后回车就可进入安装

这里输入“yes”选择加入环境变量

安装完成!!!
运行anaconda并固定在我们桌面显示
输入:


我们安装好anaconda之后我们就可以安装配置我们的pycharm啦!
Pycharm安装
Pycharm 2019.3.3Linux资源包下载(资源名称不符,里面是该资源!请放心下载!)
建立一个文件夹用于存放我们安装包:
①在电脑上下载pycharm-professional-anaconda-2019.3.3.tar.gz的安装包,然后复制到虚拟机创建好的空文档里。(或者直接在虚拟机里下载pycharm-professional-anaconda-2019.3.3.tar.gz)

②在终端切换到放置安装包的目录后,输入解压命令,解压需要时间。
解压命令:如下
解压过程:
:
③解压完成后,生成文件夹里面的文件
破解准备:修改host文件

④进入解压的文件夹,然后进入bin目录下,可以看到一个pycharm.sh的执行文件
⑤在bin目录下执行启动命令(./pycharm.sh),启动pycharm,启动后会有弹窗(类似在Windows下打开安装包),选择第二项Do not import settings,然后点击ok,如图:
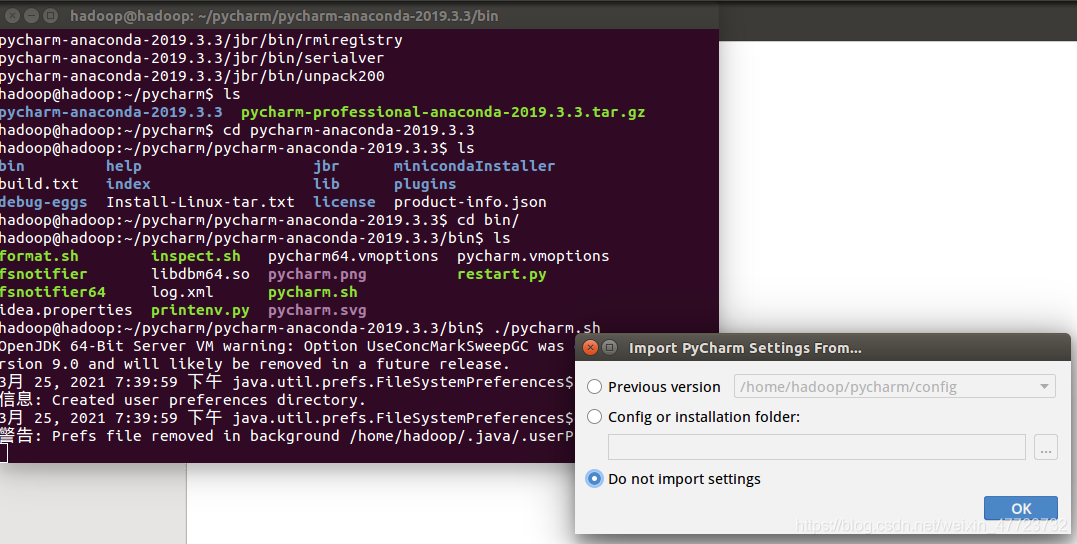
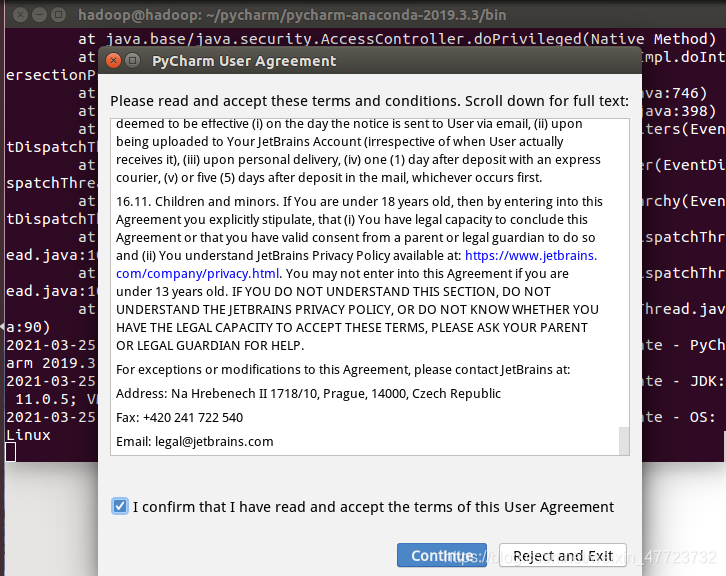
⑥OK后,会有一个协议的弹窗,勾选后点击continue就可以进行下一步
⑦数据分享。这个可以自行选择,表示是否愿意共享到社区,在这里选择后者,“Don’t send”,继续进入下一步。

对于专业版的破解,我们首先在Anaconda安装好之后吧,我们再去配置环境,这里
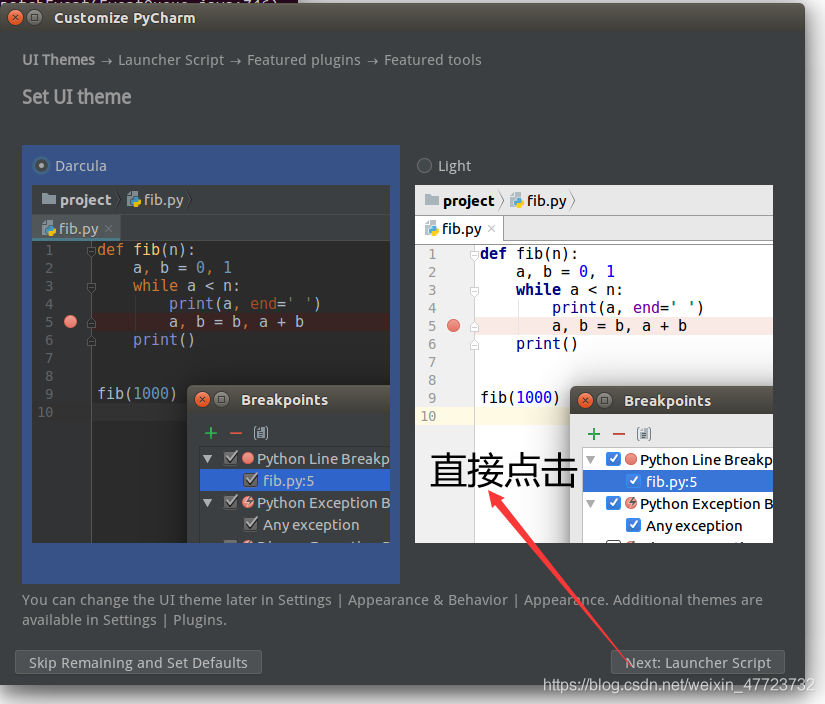

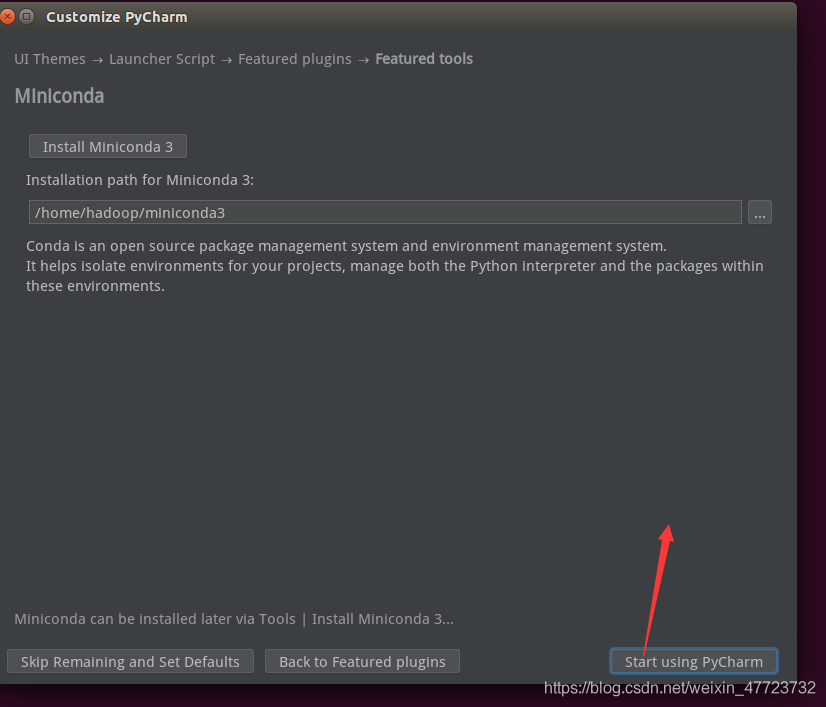
到了这一步,我们可以不着急去破解,因为我们要利用Anaconda这个编译器,所以确定好环境之后我们再去破解,之前我们已经安装好了anaconda了,下载就可以开始破解和配置了!
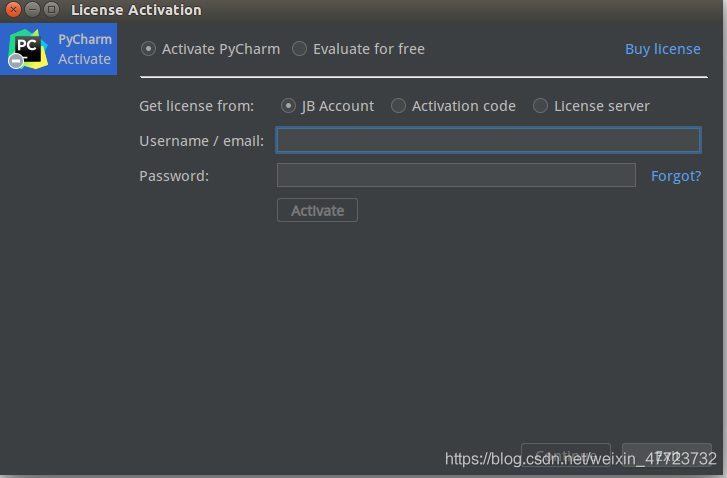
pycharm配置与破解
点击此处破解包下载!!!!(资源名称不符是故意设置的,请放心下载!)
前方高能!破解版注意哟!!首先要下载一个破解版的资源
点击此处下载资源!!!

需要点击License Avtivate窗口的“Evaluate for free”免费试用,然后再创建一个空项目,这样就可以进入到pycharm的工作页面
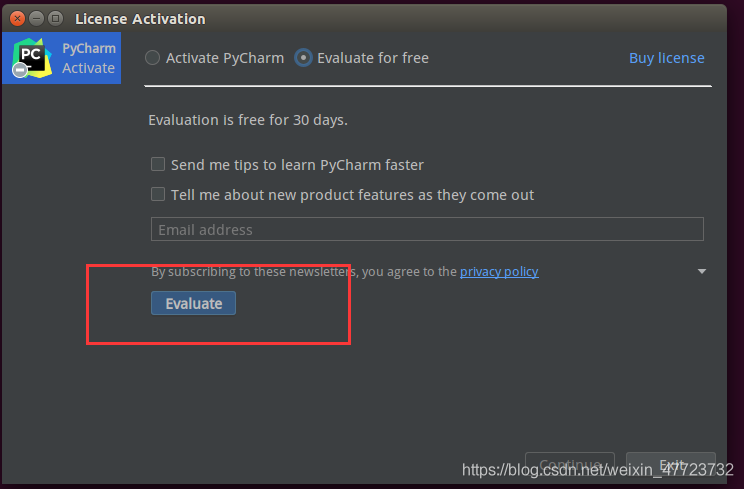
接下来我们就开始配置环境了,用于我们的anaconda的组件,包括其他的,这个也非常的重要!!

自己建立一个工程

初始化与加载!!!时间可能有点长,耐心一点哟
好像发现搞错了,我们是要用anaconda环境的,搞错了,再来!
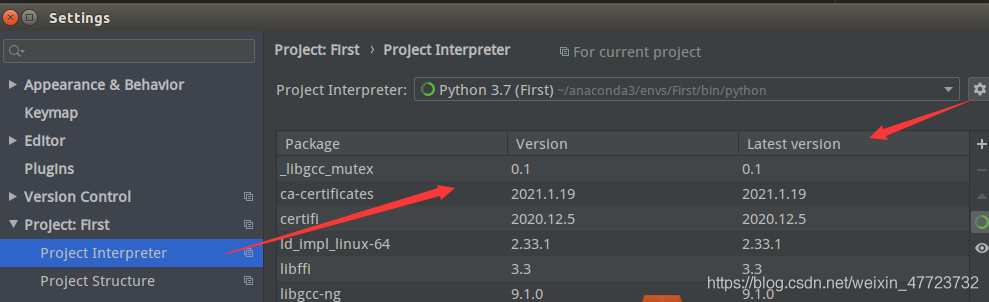
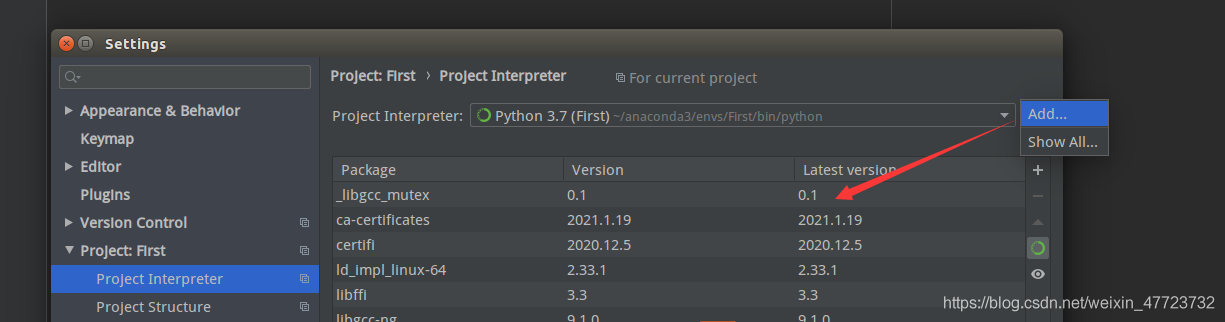
点击方框右侧的“+”按钮,在弹出的小窗口,选择Existing environment,点击…浏览选择anaconda解释器的位置。
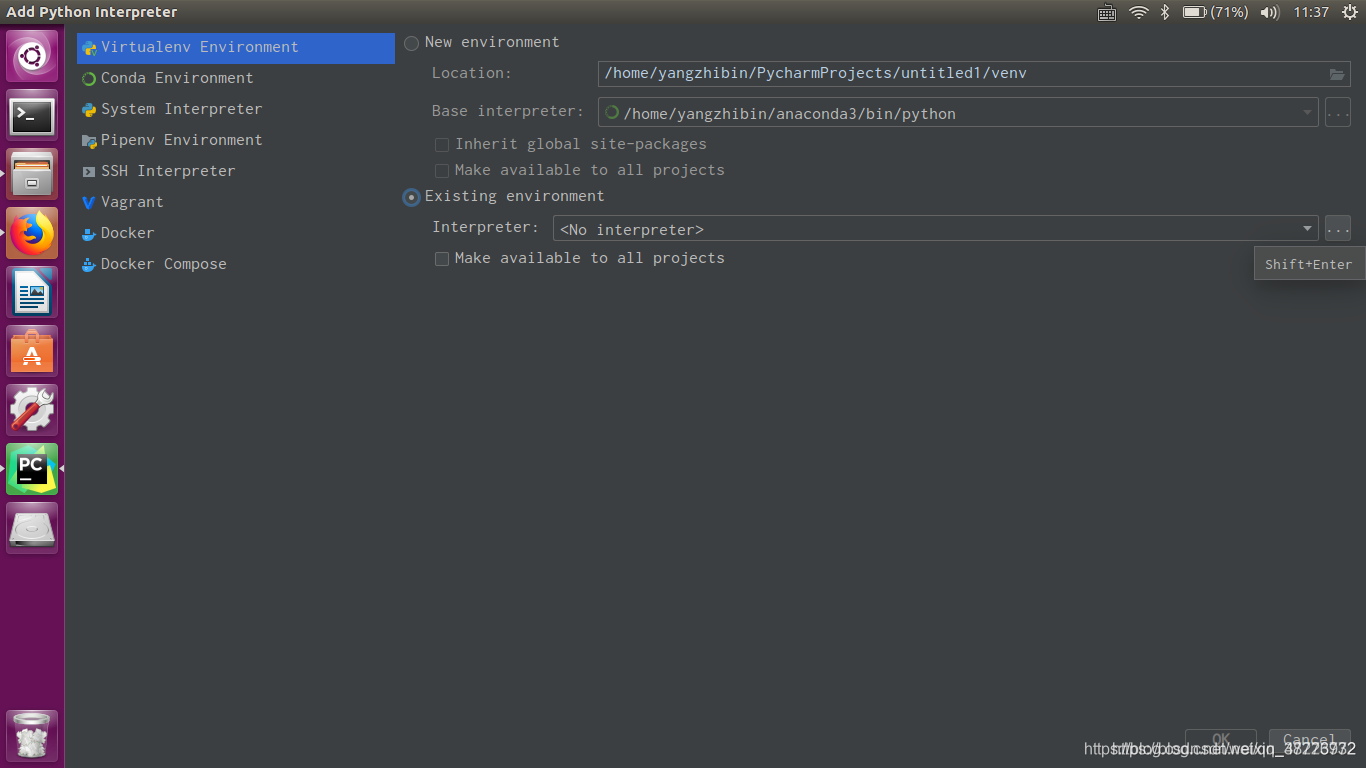
在浏览中找到你的anaconda文件夹,选择bin目录里的python解释器,点击OK


这里就开始初始化了,可能要等一段时间,系统需要加载anaconda里面的所有包
破解步骤
然后把analysis压缩包拉倒IDE的界面中
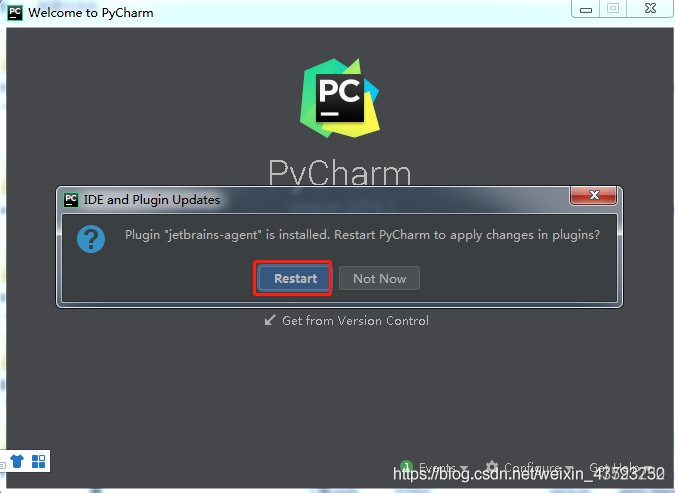
如果已经打开项目,直接将 jetbrains-agent-latest.zip包拖到代码区,出现下面的小框即可

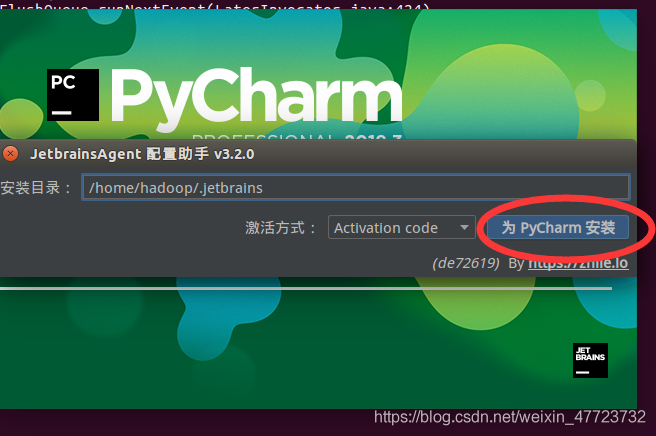
选择是,然后重启
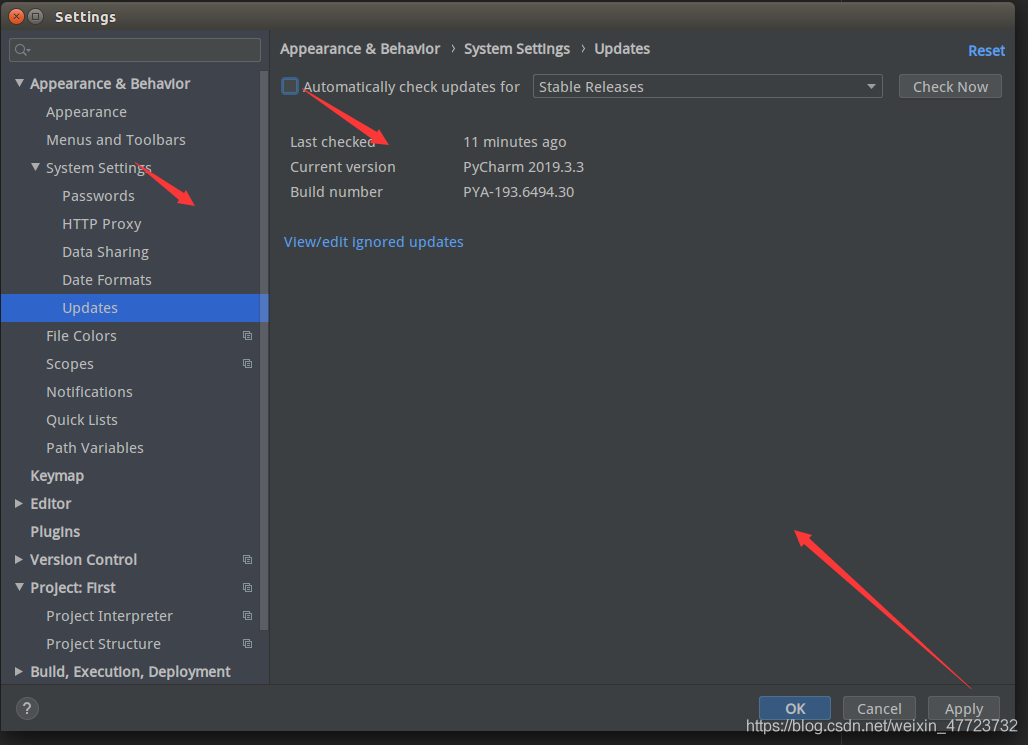
勾选掉自动更新
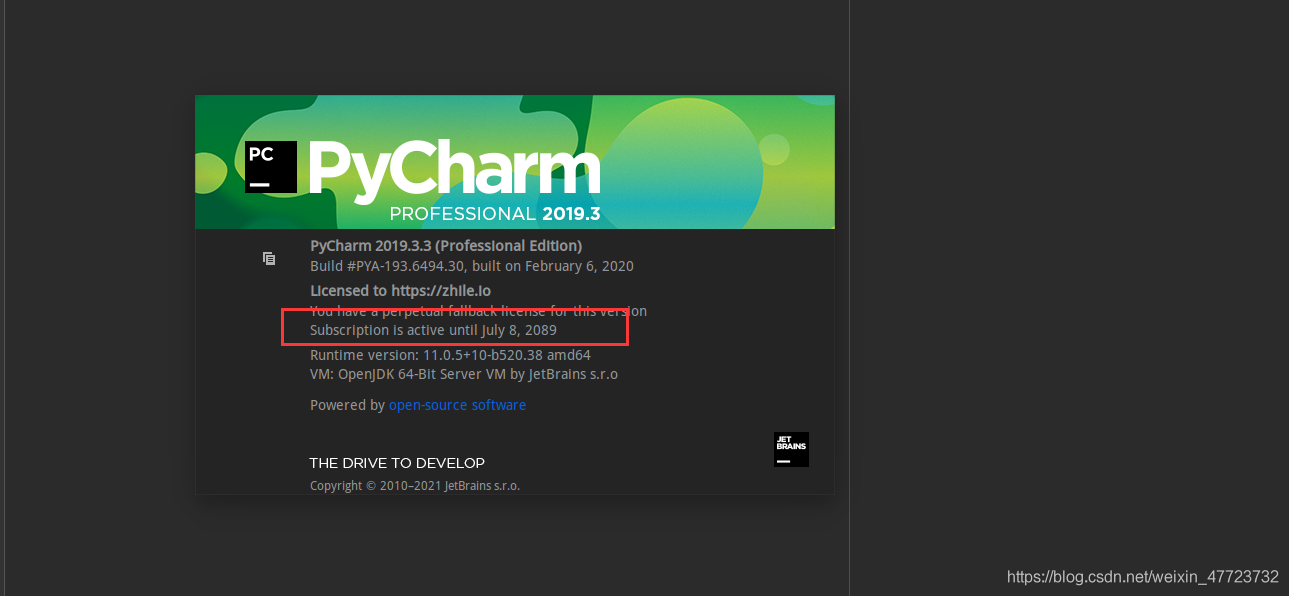
哈哈哈!破解成功了,就是这么粗暴简单,你知道了吗!!!
注意:最开始我们破解的时候可能,会有时候不稳定,我们多试几次就好了,每次点击进去的时候,如果不能,我们就可以重复上面的步骤,即可!!
Anaconda python版本降级
因为我们安装的是3.8,但是使用pyspark我们需要3.7的,不信我们可以运行一下
首先安装第三方库:
首先使用清华镜像网址打开通道,这样速度更快
使用命令:

安装出错多试几次,可能是网速的原因,如果实在不可以,推荐下面方法:

OK!!!
添加虚拟机spark环境变量
运行代码出现:
ValueError: Couldn't find Spark, make sure SPARK_HOME env is set or Spark is in an expected location (e.g. from homebrew installation).
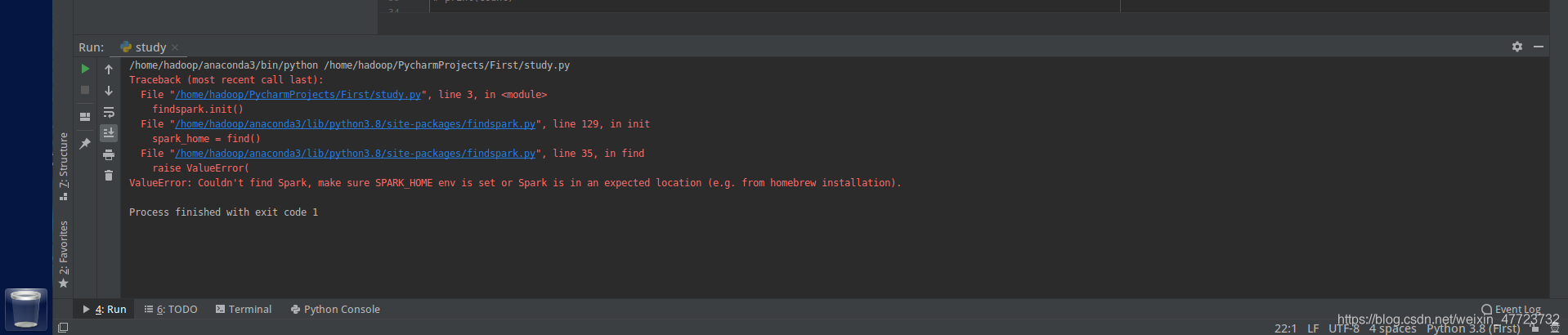
这个是因为我们没有在pycharm里面加入环境变量,步骤如下:

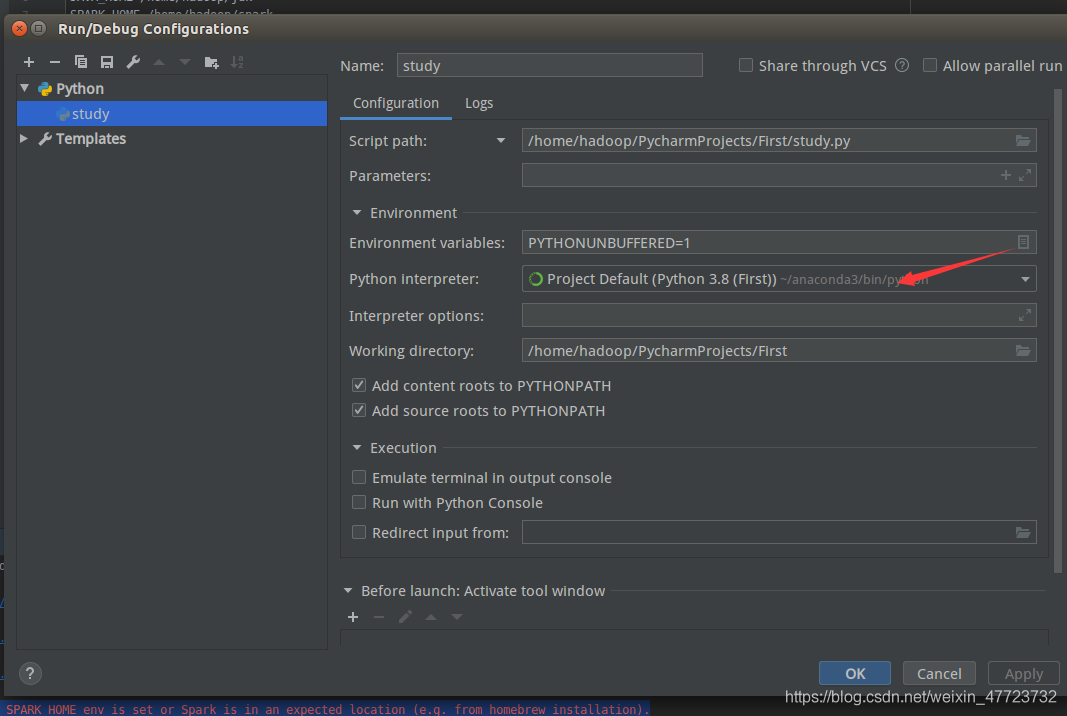
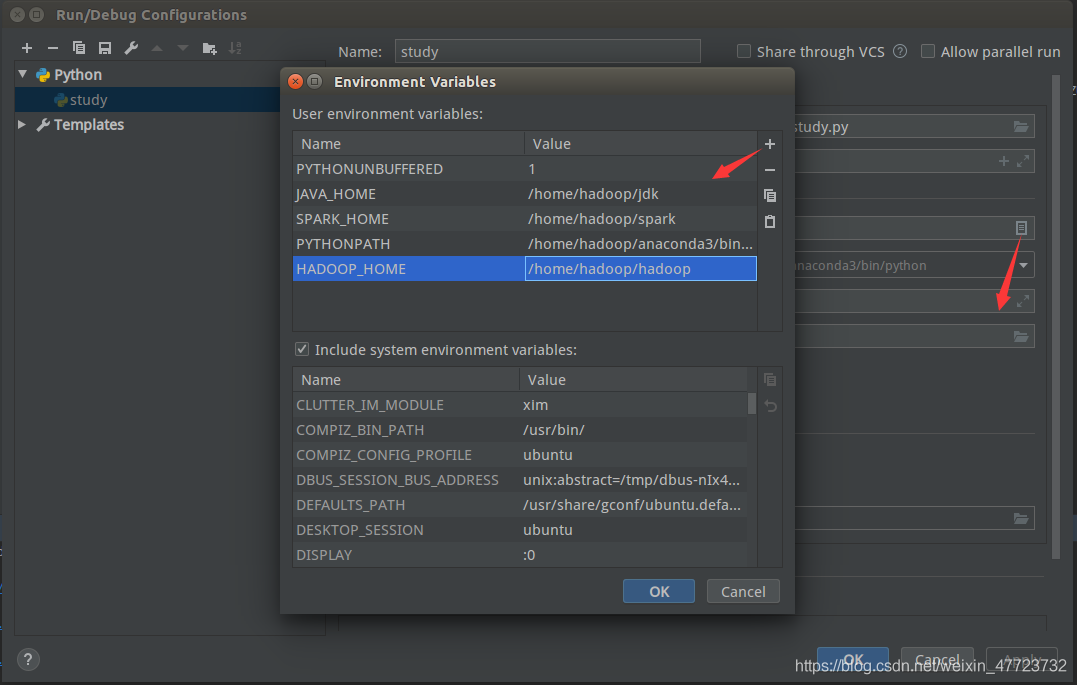
一定要注意空格!!!!!!!不知道坑了不少人,我也是其一!
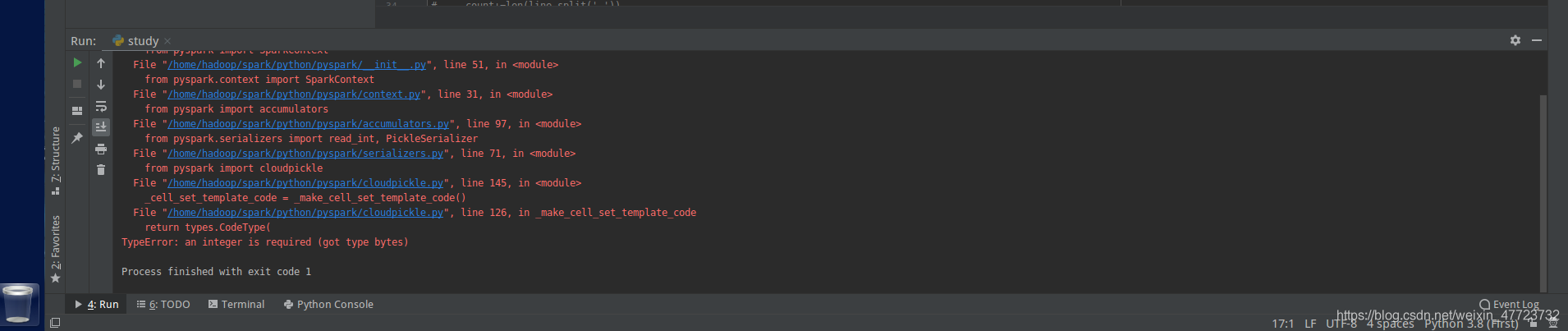
经过一番搜集,发现是版本的原因,所以降级!
python 3.8 降级 3.7
打印如上错误异常是因为 spark 2.4.x 还不支持 python 3.8 版本,需要将执行代码的 python 环境降级到 3.7 版本或以下即可解决。

慢慢的等待它的降级..........



运行spark的必要代码:为了找到本地存在spark

OK!在虚拟机可以运行pyspark的代码了!
下一步我们配置pycharm的参数,为了我们日常开发的一些美观,比如字体,比如背景图这些:
Pycharm美工配置
调整字体,帮助我们自然认识代码的艺术
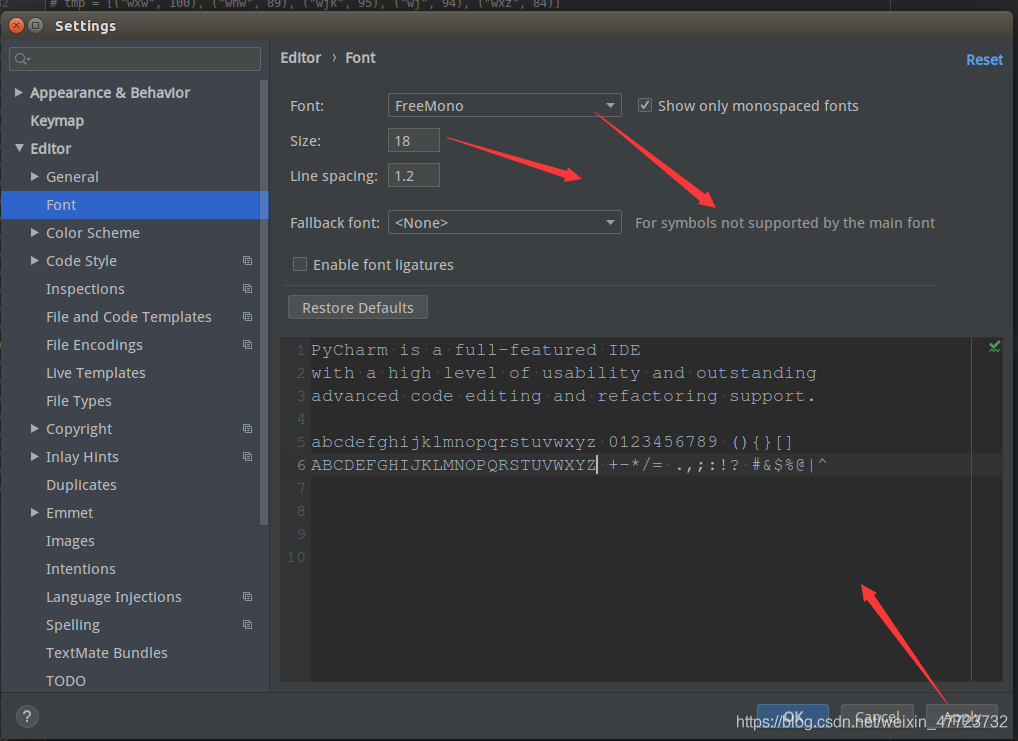
配置代码主题
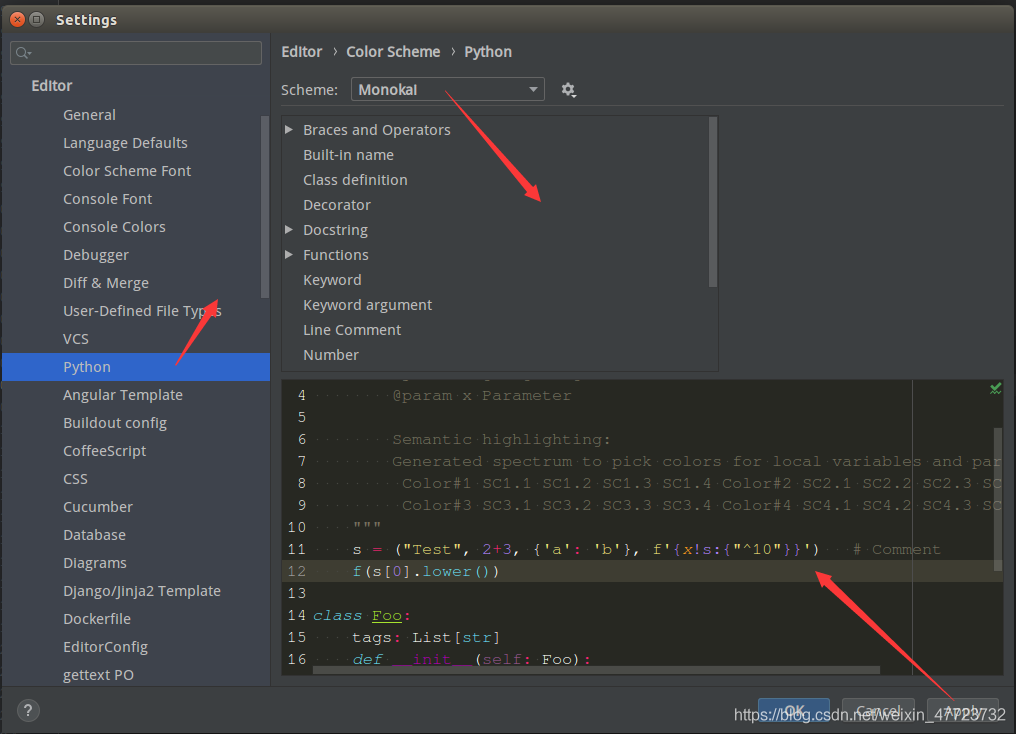
配置背景图
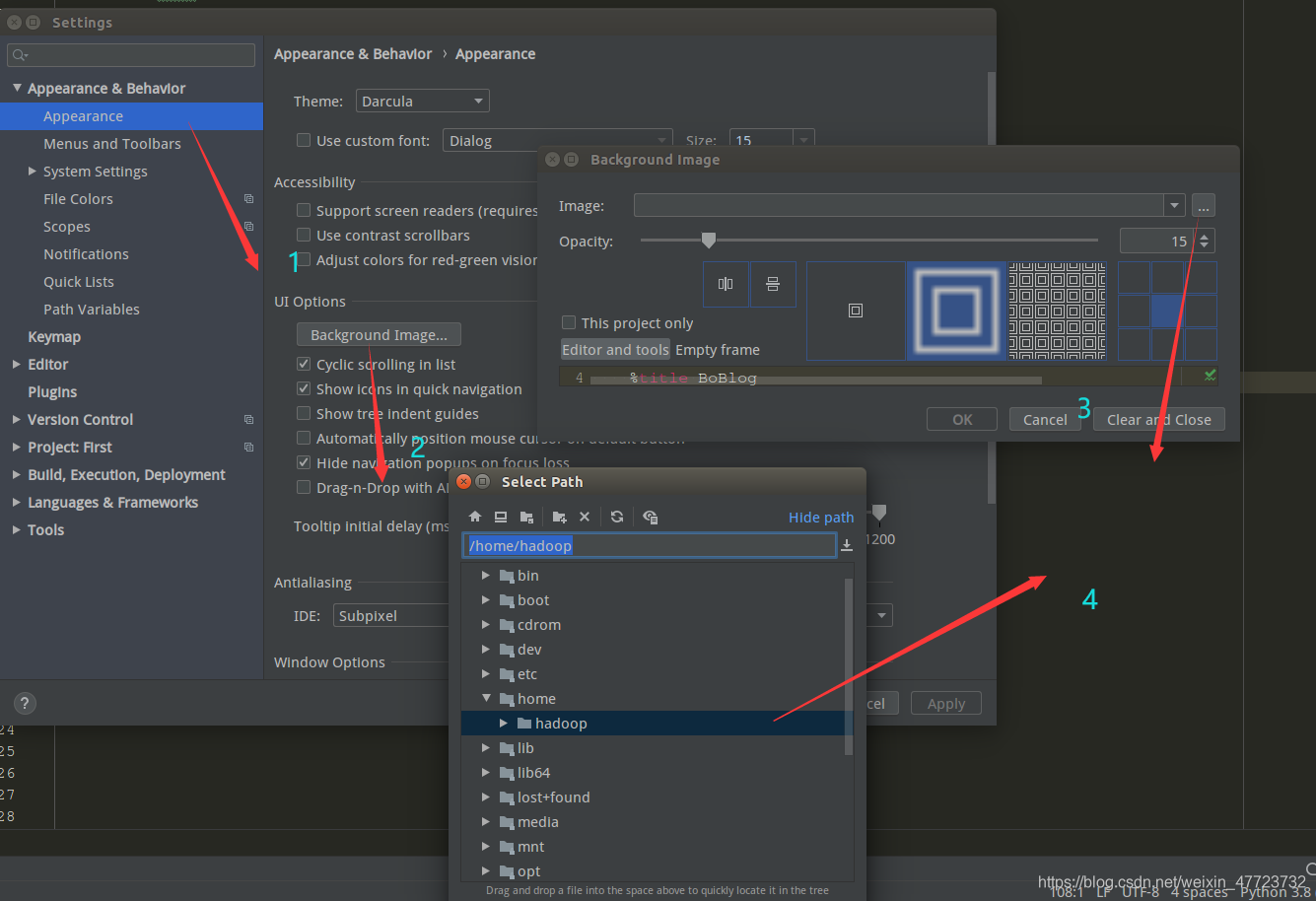
更换如下:

都可以自己更改自己喜欢的壁纸,推荐下面的壁纸,很好看的!男生,女生喜欢的类型都有:
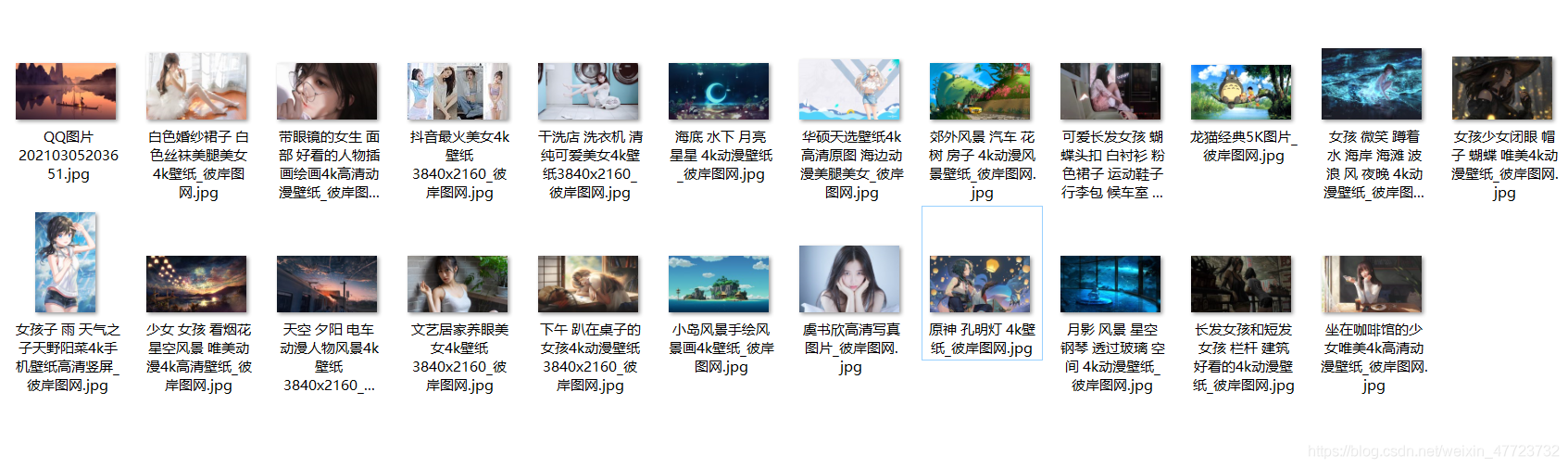
点击此处下载,图片资源!!
对于在虚拟机安装anaconda与pycharm就已经完成了!所有的开发环境都已准备就绪,大数据的时代,谁与争锋,武功很重要,武器更重要!

每文一语
只有经济独立,才能灵魂挺拔!
合智互联客户成功服务热线:400-1565-661



留言评论
暂无留言