


问题场景
客户作业场景如下图所示,从DMS kafka通过DLI Flink将业务数据实时清洗存储到DWS。

其中,DMS Kafka 目标Topic 6个分区,DLI Flink作业配置taskmanager数量为12,并发数为1。
问题现象
客户在DLI服务共有三个相同规格的队列,该作业在其中003号队列上运行正常,在001和002号队列上都存在严重的反压导致数据处理缓慢。作业列表显示如下图,可以看到Sink反压状态正常,Souce和Map反压状态为HIGH。

问题分析
根据反压情况分析,该作业的性能瓶颈在Sink,由于Sink处理数据缓慢导致上游反压严重。
该作业所定义的Sink类型为DwsCsvSink,该Sink的工作原理如下图所示:Sink将结果数据分片写入到OBS,每一分片写入完成后,调用DWS insert select sql将obs路径下该分片数据load到dws。

因此性能瓶颈出现在分片数据写入到OBS这一步。但问题来了,写同一个桶,为什么在不同队列上的表现不一致?
为此,我们排查了各个队列的CPU、内存和网络带宽情况,结果显示负载都很低。
这种情况下,只能继续分析FlinkUI和TaskManager日志。
数据倾斜?
然后我们在FlinkUI任务情况页面,看到如下情况:Map阶段的12个TaskManager并不是所有反压都很严重,而是只有一半是HIGH状态,难道有数据倾斜导致分配到不同TaskManager的数据不均匀?

然后看Source subTask详情,发现有两个TaskManager读取的数据量是其他几个的几十倍,这说明源端Kafka分区流入的数据量不均匀。难道就是这么简单的问题?
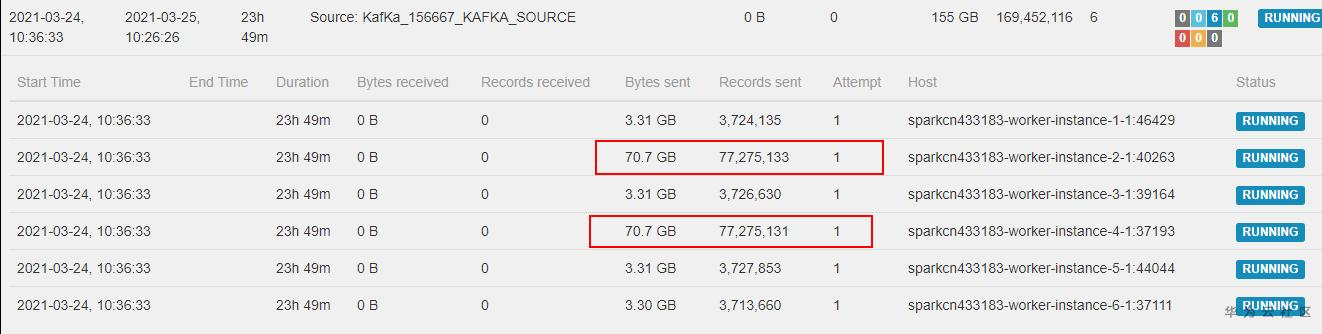
很不幸并不是,通过进一步分析源端数据我们发现Kafka 6个分区数据流入记录数相差并不大。这两个Task只是多消费了部分存量数据,接收数据增长的速度各TaskManager保持一致。
时钟同步
进一步分析TaskManager日志,我们发现单个分片数据写入OBS竟然耗费3min以上。这非常异常,要知道单个分片数据才500000条而已。

进一步通过分析代码发现如下问题:在写OBS数据时,其中一个taskmanager写分片目录后获取该目录的最后修改时间,作为处理该分片的开始时间,该时间为OBS服务端的时间。

后续其他taskmanager向该分片目录写数据时,会获取本地时间与分片开始时间对比,间隔大于所规定的转储周期才会写分片数据。
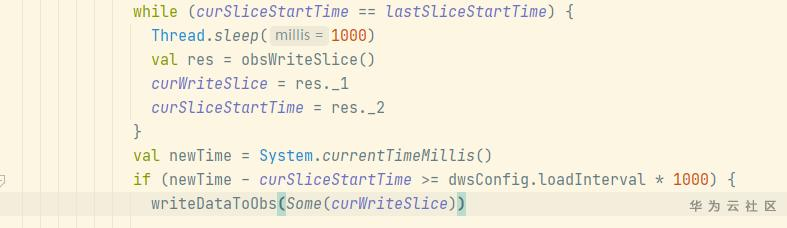
如果集群节点NTP时间与OBS服务端不同步,本地时间晚于OBS服务端时间,则会造成写入OBS等待。
后续排查集群节点,发现6个节点中一半时间同步有问题,这也和只有一半taskmanager反压严重的现象相对应。
问题修复
在集群节点上执行如下命令,强制时间同步。
systemctl stop ntp
ntpdate ntp.myhuaweicloud.com
systemctl start ntp
systemctl status ntp
date
NTP同步后,作业反压很快消失,故障恢复。





留言评论
暂无留言